
In the last post we talked about that we can fine tune a BERT model using below two techniques –
- Update the weights of the pre-trained BERT model along with the classification layer.
- Update only the weights of the classification layer and not the pre-trained BERT model. This process becomes as using the pre-trained BERT model as a feature extractor.
Also in the last post , we did hands-on coding part on the first process where we have updated the weights of the pretrained BERT model along with the classification layer. In this post we will talk about how to only update the weights of the classification layer and not the pre-trained BERT model. Using the pre-trained model we will extract the features then we will add a classifier on top of it as shown below –
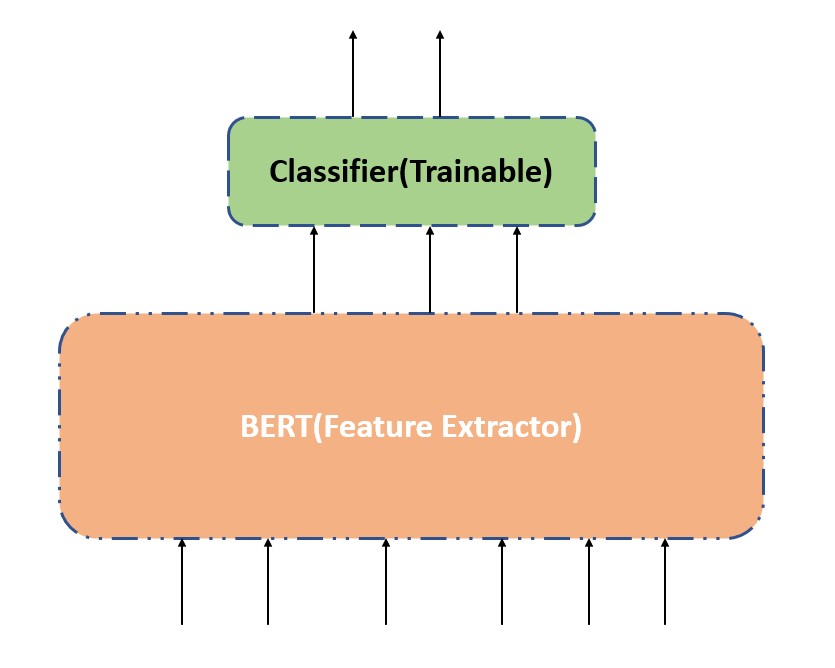
The dataset we will use is a kaggle TweetSentiment_Analysis dataset as used in the last post.
# Importing the required Library
import transformers
import torch
import numpy as np
from torch.nn import functional as F
import pandas as pd
import tqdm
# Reading the dataset with no columns titles and with latin encoding
df_raw = pd.read_csv('../input/sentiment140/training.1600000.processed.noemoticon.csv', encoding = "ISO-8859-1", header=None)
# As the data has no column titles, we will add our own
df_raw.columns = ["label", "time", "date", "query", "username", "text"]
# Ommiting every column except for the text and the label, as we won't need any of the other information
df = df_raw[['label', 'text']]
label_dict = {4 : 1 , 0 : 0}
df.loc[:,'label'] = df['label'].map(label_dict)
#doing the train / test split
from sklearn.model_selection import train_test_split
train_texts, val_texts, train_labels, val_labels = train_test_split(df['text'].values, df['label'].values, test_size=.2)
Next few steps are same as last post we will tokenize the train and validation texts and then create datasets and dataloaders.
from transformers import AutoTokenizer,AdamW,AutoModel
tokenizer = AutoTokenizer.from_pretrained('distilbert-base-uncased')
train_input_ids = []
train_attention_mask = []
for text in tqdm.tqdm(train_texts):
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=64,
padding = 'max_length',
truncation = True,
return_attention_mask= True,
return_tensors='pt')
train_input_ids.append(encoding['input_ids'])
train_attention_mask.append(encoding['attention_mask'])
train_input_ids = torch.cat(train_input_ids,dim=0)
train_attention_mask = torch.cat(train_attention_mask,dim=0)
val_input_ids = []
val_attention_mask = []
for text in tqdm.tqdm(val_texts):
encoding = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=64,
padding = 'max_length',
return_attention_mask= True,
truncation = True,
return_tensors='pt')
val_input_ids.append(encoding['input_ids'])
val_attention_mask.append(encoding['attention_mask'])
val_input_ids = torch.cat(val_input_ids,dim=0)
val_attention_mask = torch.cat(val_attention_mask,dim=0)
# creating the train and validation datasets first then dataloaders
train_dataset = torch.utils.data.TensorDataset(train_input_ids,
train_attention_mask,
torch.tensor(train_labels,dtype=torch.long))
val_dataset = torch.utils.data.TensorDataset(val_input_ids,
val_attention_mask,
torch.tensor(val_labels,dtype=torch.long))
train_loader = torch.utils.data.DataLoader(train_dataset,shuffle=True,batch_size=32)
val_loader = torch.utils.data.DataLoader(val_dataset,shuffle=False,batch_size=32)
# selecting the device based on GPU availability
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
In the last post we used the below statement to import the bert-pretrained model for sentiment analysis as shown below –
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased')
This pretrained model is specialized for SequenceClassification and it already includes the classification layer along with feature extractor. In this tutorial we want to use BERT for the feature extraction purpose and then on top of it we want to add a trainable classifier. For this purpose we will import the pre-trained model from AutoModel class from tranformers library.We will freeze the weights for this pre-trained model. Freezing the weights is same as making this part of the model non trainable(required_grad=False i.e. no gradients calculation) , as shown in the below steps –
# Pretrained bert model for feature extraction
bert = AutoModel.from_pretrained('bert-base-uncased')
# freeze all the parameters
for param in bert.parameters():
param.requires_grad = False
print(bert)
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(2): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(3): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(4): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(5): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(6): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(7): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(8): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(9): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(10): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(11): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
# let's see if we pass one input_ids and mask to the BERT model, how the o/p looks like
for batch in train_loader:
output = bert(batch[0],batch[1])
break
print(output)
BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 7.6130e-02, 3.0028e-01, 1.9767e-01, ..., -4.6484e-01,
6.5636e-01, 2.2707e-01],
[ 1.0437e+00, 5.4522e-01, 5.0423e-01, ..., -1.2399e-01,
6.6002e-01, 4.3423e-01],
[ 2.5797e-01, -2.0083e-01, 3.5641e-01, ..., -8.8620e-01,
-6.7701e-01, -2.9842e-01],
...,
[-7.8971e-02, -1.2226e-01, -8.3569e-03, ..., -1.8645e-01,
-3.0247e-02, 2.6681e-01],
[-2.7178e-04, 2.9616e-02, -5.3214e-04, ..., -1.6130e-01,
-2.0233e-01, -3.1436e-02],
[-6.2698e-02, 9.6016e-02, 1.2038e-01, ..., 2.0962e-01,
-4.1216e-01, -4.7183e-01]],
[[ 2.2744e-01, -1.7503e-01, 6.0626e-01, ..., -3.6281e-01,
1.5698e-01, 2.3664e-01],
[ 8.5164e-01, -3.9539e-02, 1.1516e+00, ..., -5.8906e-01,
7.4140e-01, -7.7569e-01],
[-1.5091e-01, 6.0787e-01, 1.0695e+00, ..., -1.0550e+00,
-2.0334e-01, 9.3699e-02],
...,
[ 3.1049e-01, 2.4796e-01, 9.0660e-01, ..., 2.9934e-01,
-7.0334e-02, 2.9905e-02],
[ 1.1044e-01, -2.1328e-01, 5.9599e-01, ..., 2.9944e-01,
-5.5401e-02, -9.2809e-02],
[ 3.0435e-01, -1.0327e-01, 5.8737e-01, ..., -2.6026e-02,
1.3282e-02, -2.7680e-01]],
[[-3.8740e-02, 3.8283e-01, 1.3519e-01, ..., -4.7261e-01,
2.9040e-01, 7.4302e-02],
[ 1.2880e+00, 4.6513e-01, 4.9811e-01, ..., -6.0443e-02,
5.2943e-01, 2.5371e-02],
[ 4.4679e-01, 2.4395e-01, 9.2009e-01, ..., -1.3193e+00,
-1.7171e-03, -4.6538e-01],
...,
[-2.7403e-02, 1.1322e-01, 3.7078e-01, ..., -1.4278e-01,
-1.0403e-01, 3.1841e-02],
[ 3.1821e-01, 1.8279e-01, 5.1534e-01, ..., -2.1147e-01,
5.4801e-02, -1.9411e-01],
[ 1.2656e-01, 3.0878e-01, 4.1903e-01, ..., -7.5436e-02,
-1.9948e-01, -2.8558e-01]],
...,
[[-2.0281e-01, 3.5621e-01, -7.0264e-02, ..., -5.5653e-01,
3.5597e-01, 5.8795e-01],
[ 8.8901e-01, 1.2949e+00, 6.7760e-01, ..., -7.7929e-01,
2.3766e-01, -1.1659e-02],
[ 6.9488e-01, 1.6480e-01, 3.5486e-01, ..., -8.7871e-01,
1.7530e-01, 8.2788e-01],
...,
[ 3.2618e-02, -3.0351e-01, 8.9549e-02, ..., -1.6387e-01,
-1.3008e-02, 2.5270e-01],
[-2.3254e-01, -1.7207e-02, 1.6763e-01, ..., 3.7357e-02,
-5.3747e-02, 1.4310e-01],
[ 1.8346e-01, -1.6781e-01, 1.2193e-01, ..., 2.4727e-01,
2.3594e-02, 4.1763e-01]],
[[-9.2725e-02, 3.0266e-01, 3.8117e-01, ..., -3.6654e-01,
3.2090e-01, 6.1811e-01],
[-1.6589e-01, 2.5344e-01, 2.6113e-01, ..., -5.4005e-01,
4.3820e-01, -1.7630e-01],
[-8.6363e-01, 9.1309e-02, 3.2616e-01, ..., -6.7615e-01,
5.6554e-03, 1.6757e-01],
...,
[ 1.4002e-01, 1.5428e-01, 2.2178e-01, ..., 8.9925e-02,
1.8572e-01, -1.5675e-01],
[ 8.8376e-02, 1.6205e-01, 2.6797e-01, ..., -3.9465e-02,
1.4420e-01, -2.9028e-01],
[ 1.9893e-01, 2.1795e-01, 5.0799e-01, ..., 6.4940e-01,
1.0356e-01, -2.7263e-01]],
[[ 3.3226e-02, 9.8368e-02, -9.4797e-02, ..., -4.8308e-01,
3.1923e-01, 3.6139e-01],
[ 1.1744e+00, 3.4631e-01, 1.6627e-01, ..., -1.5208e-01,
3.8729e-01, -3.8763e-01],
[ 2.8756e-02, 3.0364e-01, 4.5408e-01, ..., -2.2403e-01,
2.7785e-01, -6.8523e-01],
...,
[ 1.2506e-01, -1.2031e-01, 3.0681e-01, ..., -8.4977e-02,
2.6747e-03, -4.9059e-02],
[ 5.4640e-03, -1.2106e-01, 2.2333e-01, ..., -1.5277e-01,
-7.6455e-02, -2.8878e-03],
[ 1.7237e-02, 1.0030e-01, 1.5545e-01, ..., -1.0980e-02,
-3.2600e-01, 3.4269e-02]]]), pooler_output=tensor([[-0.9039, -0.4003, -0.7570, ..., -0.3390, -0.6723, 0.9357],
[-0.6973, -0.3033, -0.6883, ..., -0.3146, -0.5737, 0.8383],
[-0.7385, -0.3278, -0.4051, ..., 0.0765, -0.6580, 0.8070],
...,
[-0.5511, -0.2757, -0.8041, ..., -0.6374, -0.6196, 0.7604],
[-0.7697, -0.2591, -0.6360, ..., -0.1250, -0.5208, 0.8672],
[-0.7645, -0.5344, -0.9521, ..., -0.7028, -0.7307, 0.7830]]), hidden_states=None, past_key_values=None, attentions=None, cross_attentions=None)
We are interested in the pooler_output and not the last_hidden_state , this pooler_output we will send to the newly added classification layer –
print(output['pooler_output'])
tensor([[-0.9039, -0.4003, -0.7570, ..., -0.3390, -0.6723, 0.9357],
[-0.6973, -0.3033, -0.6883, ..., -0.3146, -0.5737, 0.8383],
[-0.7385, -0.3278, -0.4051, ..., 0.0765, -0.6580, 0.8070],
...,
[-0.5511, -0.2757, -0.8041, ..., -0.6374, -0.6196, 0.7604],
[-0.7697, -0.2591, -0.6360, ..., -0.1250, -0.5208, 0.8672],
[-0.7645, -0.5344, -0.9521, ..., -0.7028, -0.7307, 0.7830]])
print(output['pooler_output'].shape) # batch size , feature size
torch.Size([32, 768])
print(output['last_hidden_state'].shape) # three dimensional hidden layer o/p
torch.Size([32, 64, 768])
Next we will build a Pytorch model class which will take the BERT feature extractor as input and add the classifier on top of it.
class BERT_Custom_Clf(torch.nn.Module):
def __init__(self, bert):
super(BERT_Custom_Clf, self).__init__()
self.bert = bert
# dropout layer
self.dropout = torch.nn.Dropout(0.1)
# relu activation function
self.relu = torch.nn.ReLU()
# fully connected layer 1
self.fc1 = torch.nn.Linear(768,512)
# fully connected layer 2 (Output layer)
self.fc2 = torch.nn.Linear(512,2)
#softmax activation function
self.softmax = torch.nn.LogSoftmax(dim=1)
#define the forward pass
def forward(self, input_id, attention_mask):
#pass the inputs to the model
output = self.bert(input_id, attention_mask=attention_mask)
x = self.fc1(output['pooler_output']) # passing the pooler_output to fully connected layer
x = self.relu(x)
x = self.dropout(x)
# output layer
x = self.fc2(x)
# apply softmax activation
x = self.softmax(x)
return x
# pass the pre-trained BERT to our defined architecture model = BERT_Custom_Clf(bert) # push the model to device and make it ready for training model = model.to(device) model.train() # create the optimizer optimizer = AdamW(model.parameters(), lr=5e-5) # define the loss function criterion = torch.nn.NLLLoss()
# train the model for one epoch
batch_labels = []
batch_prediction = []
for batch in tqdm.tqdm(train_loader):
optimizer.zero_grad()
input_ids = batch[0].to(device)
attention_mask = batch[1].to(device)
labels = batch[2].to(device)
outputs = model(input_ids, attention_mask)
loss = criterion(outputs,labels)
preds = torch.argmax(outputs,dim=1)
loss.backward()
optimizer.step()
batch_labels.extend(labels.cpu().numpy())
batch_prediction.extend(preds.cpu().numpy())
100%|██████████| 40000/40000 [42:24<00:00, 15.72it/s]
from sklearn.metrics import f1_score,accuracy_score
def calculate_model_performence(labels,prediction):
print('F1 Score:',f1_score(labels,prediction))
print('Accuracy :',accuracy_score(labels,prediction))
print('Training Performence')
print(calculate_model_performence(batch_labels,batch_prediction
Training Performence F1 Score: 0.7406593270216731 Accuracy : 0.738784375
# making predictions on the test dataset
batch_labels = []
batch_prediction = []
model.eval()
for batch in tqdm.tqdm(val_loader):
input_ids = batch[0].to(device)
attention_mask = batch[1].to(device)
labels = batch[2].to(device)
with torch.no_grad():
outputs = model(input_ids,attention_mask)
preds = torch.argmax(outputs,dim=1)
batch_labels.extend(labels.cpu().numpy())
batch_prediction.extend(preds.cpu().numpy())
100%|██████████| 10000/10000 [10:18<00:00, 16.16it/s]
print('Validation Performence')
print(calculate_model_performence(batch_labels,batch_prediction))
Validation Performence F1 Score: 0.769396762500276 Accuracy : 0.771578125
Running the training loop for more iteration can improve the performance on the validation set.
Thanks for reading and please comment if you have any questions.