
In the last post we talked about how to do In-context finetuning using few shot techniques, In-context finetuning works when we don’t have much data, or we don’t have access to the full model. This technique has certain limitations like the more examples you add in the prompt the context length increases a lot and there is always cut off on how much benefit you can get out in-context fine tuning.
Here comes the technique of the feature based fine tuning when we have lot of data to fine-tune LLM and we have full access to the LLM for doing any downstream task like Classification, Sentiment analysis etc. In general feature based fine tuning can be done using the below mentioned two approaches, I already have written two blog posts on these two approaches, I am attached the link of these tutorials here:
- Update the weights of the pre-trained LLM model along with the classification layer.
In practice, finetuning all layers almost always results in superior performance; however, this process is a resource intensive and time-consuming process. Hardware requirements like GPU is almost essential.
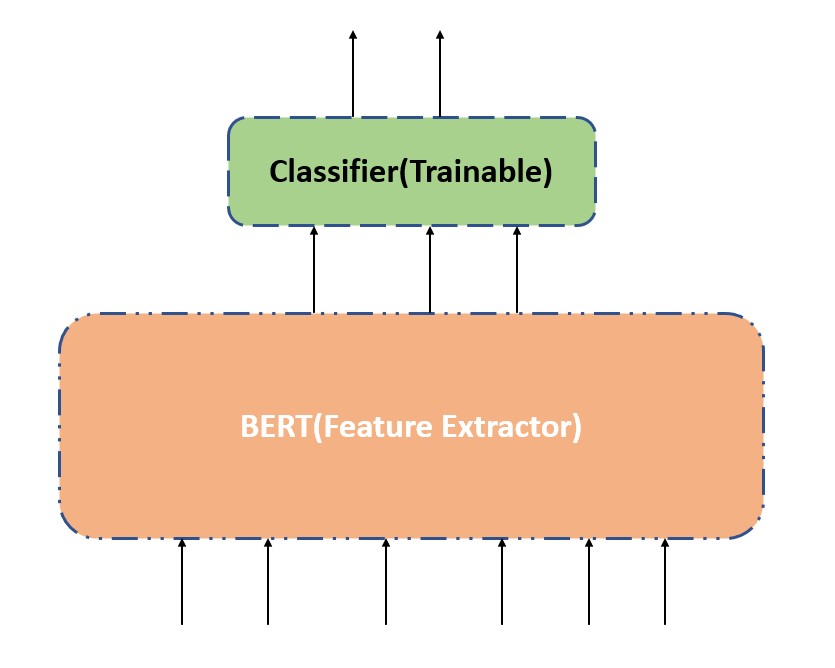
2. Update only the weights of the classification layer and not the pre-trained LLM model.
This process acts as using the pre-trained LLM model for feature extraction. This approach is much more efficient in terms of resource consumption and time required. Different heads can be trained for different downstream tasks using this approach.

From the above image we can see that feature based finetuning requires more training time to get optimal model performance and these processes are always not resource efficient finetuning approaches.
More fine-tuning approaches to come in this blog post series.
Do like, share and comment if you have any questions.