
In the last post in this series, we have gone through the inner workings of LoRA fine tuning process. In this blogpost we will use the concepts of LoRA with the quantization method. We will use the newly launched Llama2 which is one of the biggest LLM launch in the history of open-source models. Below are the steps to be used in the below given notebooks and details about each process:
- Install required packages.
- Prepare the dataset for instruction fine-tuning.
- Define quantization_config using BitsAndBytes.
- Load the Llama-2 shared model with quantization_config.
- Create the Llama-2 tokenizer.
- create the peft_config to finetune the LoRA for q,v attention metrices.
- Define the training arguments.
- create the trainer with SFTTrainer.
- train the model.
- Inference phase.
Before start coding the whole process, let’s understand few of concepts which we are yet to go through in this blog post series-
Data Preparation:
In this post we will use the dialogsum from hugging face dataset module. Dataset has 4 features which is divided in the train, test and validation dataset. Features are – [‘id’, ‘dialogue’, ‘summary’, ‘topic’]. Our interest of features are dialogue and summary. Basic we trying to fine tune our model for a text summarization task using this dataset. We will prepare the dataset in such a way that it will be used for instruction finetuning. Instruction fine-tuning uses a set of labeled examples in the form of {prompt,instruction,input,output} pairs to further train the pre-trained model in for a particular task. Below function is self-explanatory for the data preparation step.

Quantization:
With the rapid development of LLM, its feels like every other day we are getting new LLMs with are indeed very large with lot of parameters. Most challenging aspect is to fit these models with minimum hardware requirements like a single GPU. For example, to fine-tune BLOOM-176B, you’d need 72 GPUs (8x 80GB A100 GPUs). Lot of research is going to find ways to fit these models in easily accessible Hardwares. One such way is Quantization. To understand this process let’s first understand the data types which are being used and how they are represented. Size of any model would highly be deepened on the number of parameters and the precision (float32, float16 or bfloat16) of these parameters. Idea is to reduce the model size using lower precision without affecting the model performance as shown below-
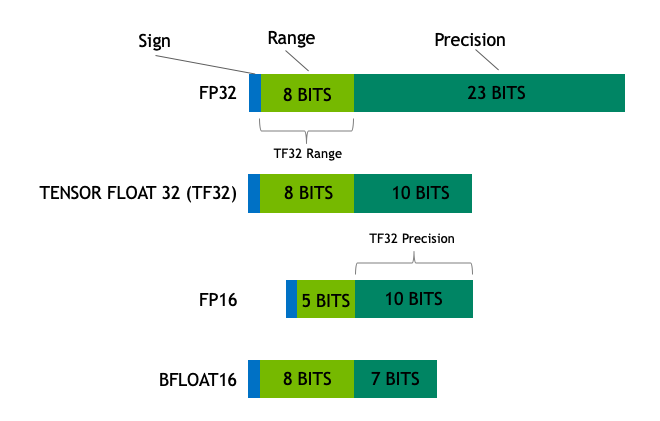
- FP32: 8 bits are reserved for the “exponent”, 23 bits for the “mantissa” and 1 bit for the “sign” of the number. With this datatype huge range of numbers can be represented.
- FP16: 5 bits are reserved for the exponent and 10 bits are reserved for the mantissa. Due to reduction of precision lesser range of numbers can be represented. This exposes FP16 numbers
to the risk of overflowing (trying to represent a number that is very large) and underflowing (representing a number that is very small). - BF16: To tackle the problem of FP16 , BF16 has been introduced where 8 bits are reserved for the exponent (which is the same as FP32) and 7 bits are reserved for the fraction.
I hope you got an idea that using Quantization we can reduce the size of the model. There are techniques of quantization also , for more details please refer to this wonderfully written hugging face blog – https://huggingface.co/blog/4bit-transformers-bitsandbytes .We will use the bitsandbytes library to load the Llama-2 model with quantization parameters.

Llama-2:
Abstract from the Llama-2 paper by Meta:
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested,and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Get the details of the all the models available: Models – Hugging Face
Sharded Model:
Sharded model is helpful for distributed training of large pretrained models like LLMs. It is achieved by sharding the model parameters, gradients, and optimizer states across data parallel processes, and it can also offload sharded model parameters to a CPU. In this coding exercise we have used the shared model version of Llama-2 to work in a single GPU. You can see that 14 shards has been downloaded which initializing the model for the first time.

Peft config:
In the last blog post we discussed in detail that in LoRA we train task specific low rank adopters which are generally q,v metrices of attention layers and keep the everything of the pretrained model weights freezed. Using the peft library we will create new low rank adopters for q_proj and v_proj as shown below with given rank (r=8).

Training Arguments:
Using Supervised Fine-tuning Trainer (huggingface.co) (SFTTrainer) we are finetuning the Llama-2 model on out custom dataset. To keep the article short please refer for training arguments details – Trainer (huggingface.co)
Inference using QLoRA Adopters:
Once the adapter is trained you can pass the saved model in the get_peft_model function along with the original model to get the new LoRA finetuned model.

You can get an idea of the whole process how to fine-tune a Llama-2 model using QLoRA. I have run the model in Kaggle kernel with 1 GPU and whole process is working fine. I will work further refining the process to improve the QLoRA outputs.
Update: Code changes has been done to fix the repeating text output. Now the text summarization is working properly.
Do like, share and comment if you have any questions or suggestions.