
Though there is a huge hype and excitement about LLMs as they are really good at several NLP related tasks, however, they also come with few of the below mentioned issues:
Frozen in time – LLMs are “frozen in time” and lack up-to-date information. This is due to the fact that these LLMs are trained with a cutoff date and beyond that they are not aware anything, for the same reason if you can ask ChatGPT about Llama-2 they won’t be able to answer your questions with correct answers. These LLMs tends to hallucinate on these unknown questions and gives you a convincing wrong answer.
Lack of domain-specific knowledge – LLMs are trained on open-sourced datasets for generalized tasks, meaning they do not know your or any company’s private data. So again, for domain specific questions they tend to give you again convincing wrong answers.
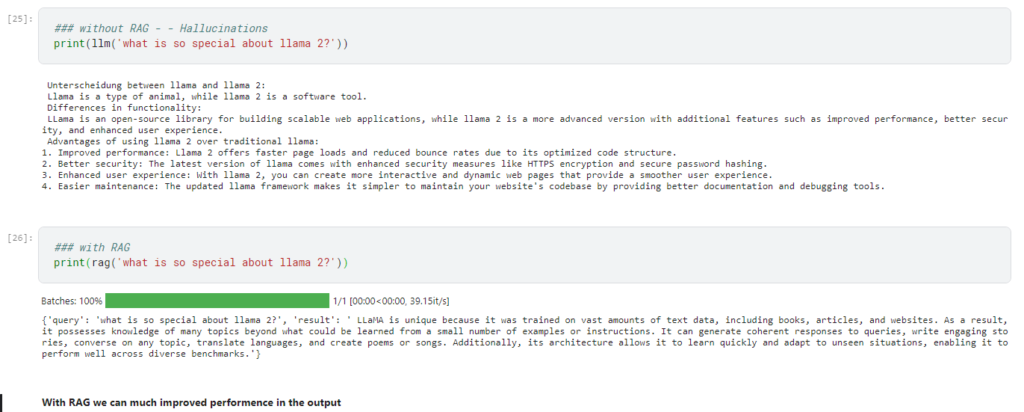
When a user sends above mentioned two types of questions to any LLM, they tend to hallucinate and give wrong answers as shown below due to the lack of context for the LLMs.

In the last blogpost we talked about how we can split documents into chunks and then create embeddings. These embeddings can be stored in any Vector Store for future uses as shown below –

These documents can be anything like:
– Domain specific documents
– Documents / Knowledge base which are related to time frame after the training cut-off date of LLM.
– Company specific sensitive internal documents.
– etc.
This type of Vector Stores can act as a knowledge base.
Retrieval Augmented Generation (RAG) can help us to tackle the above-mentioned issues, RAG using the question embedding retrieves the nearest neighbor context from the Knowledge Base and adds the context to the query. Once the context is added to the query then the RAG sends the context aware query to the LLM for relevant answer. As now the model has the correct context to answer the query, the problem of hallucination can be reduced drastically. This process also much simpler than fine tuning or full finetuning process. The whole process is shown below-
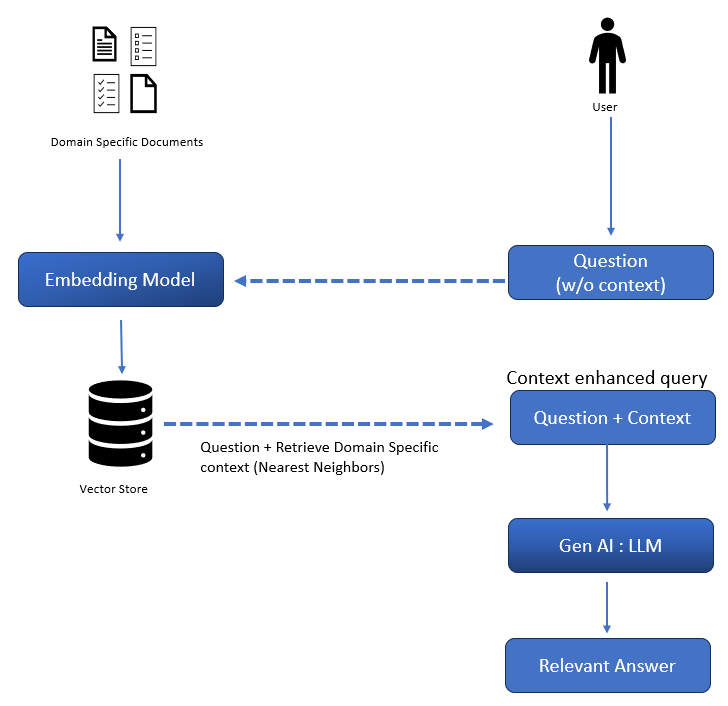
New documents can be easily added back to the Knowledge Base so the problem of ‘frozen in time’ can also be solved using the RAG methodology.
Example:
Now let’s get our hands dirty with RAG with Llama-2.
Do like, share and comment if you have any questions or suggestions.