
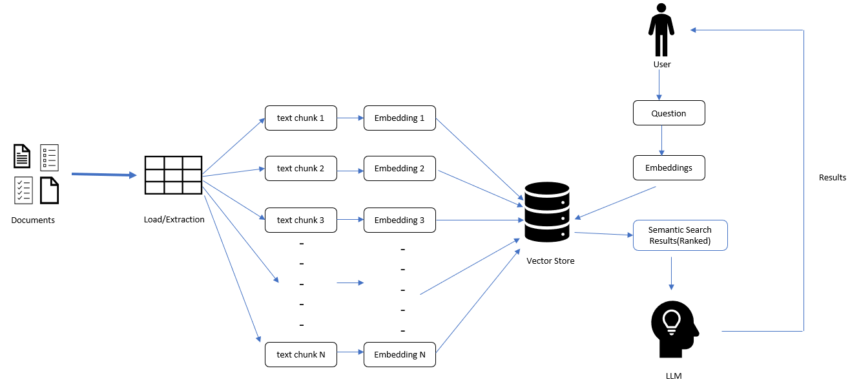
In the last few blogposts, we have gone through the basics of LLMs and different fine-tuning approaches and basics of LangChain. In this post we will mainly work with the embeddings from LLM, how we can store these LLM embeddings in Vector Store and using this persistent vector db how we can do Semantic search. Below are the high-level steps which we will do to perform the require operations –
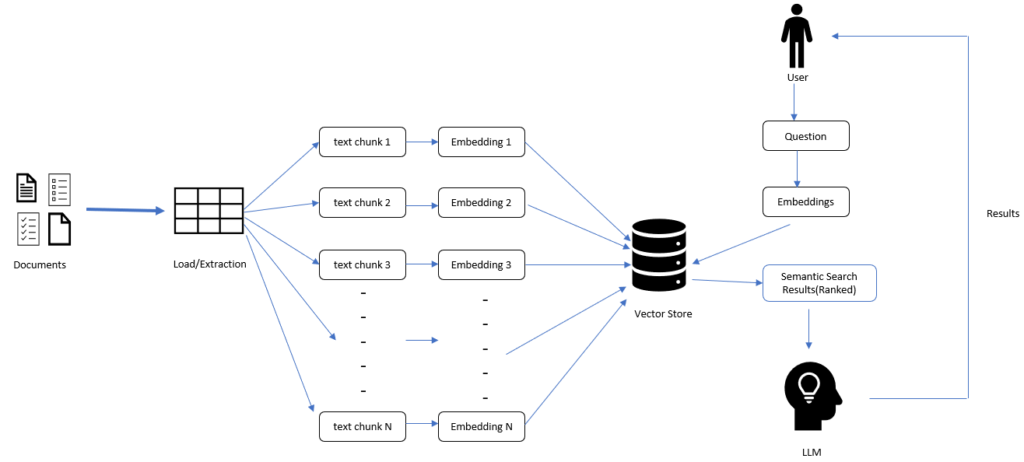
Before going into the coding, let’s go through the steps in details-
- Loading Document:
Using LangChain we can load different types of documents like pdf , csv , html etc. Follow this page to get more detailed understanding of the different document loaders – https://python.langchain.com/docs/modules/data_connection/document_loaders/
For some of the document loaders like HTMLLoader and PDF Loader we need to install dependent libraires like BeautifulSoup, pypdf. - Transform Documents to Chunks:
Once we load the document, we can access the document using page_content , however sometimes this page contents can be very large to be feed into the model (every LLM has a max input token limitations). So, we can create document chunks using below mentioned processes –
1. By using a chunk-size based on character length.
2. By using the size of input tokens. - Create Embeddings:
Using LangChain we can create numeric embeddings of the text chunks. LangChain supports different LLM embeddings like OpenAI embedding, Sentence Transformer embedding etc. - Vector Store:
Using Vector Store, we can store these document embeddings (persistent storage) for future uses like Semantic search. A user can send a search text and using LLM first we can convert that text to embeddings, using this query embedding and Vector Store embedding we can perform semantic search and retrieve the most relevant document/text using Vector Store. For this tutorial we will use the open-source vector store named chromadb (Vector stores | 🦜️🔗 Langchain). Using vector store we can easily add, update, or delete new vectors.
Now let’s get our hands dirty.
Do like, share and comment if you have any questions or suggestions.
1 thought on “Generative AI: LLMs: Semantic Search and Conversation Retrieval QA using Vector Store and LangChain 1.7”