
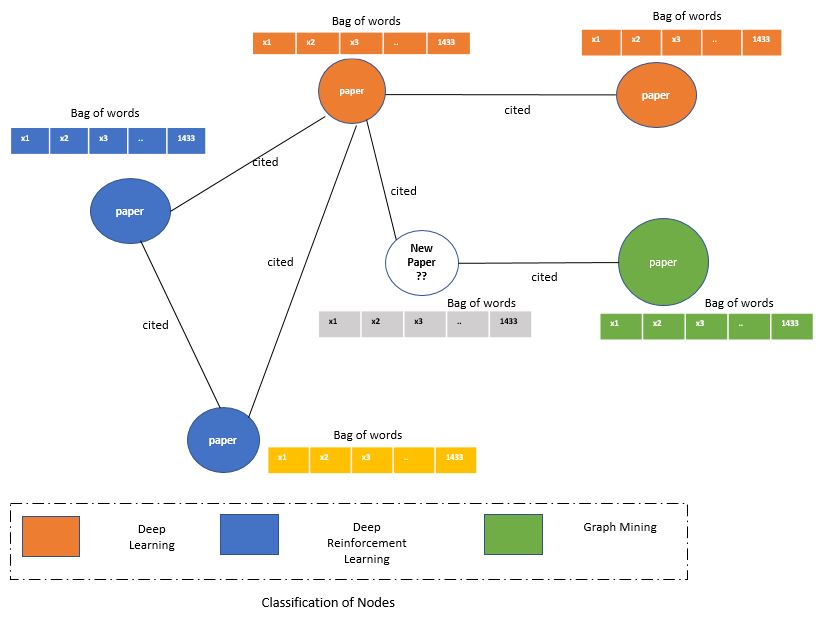
After covering the basics of GNN and PyG , now let’s start doing the actual implementation of GNN model training and inference. In this post we will use Cora citation dataset, where each node is a paper and edges refer to the citation. There seven types of papers (Example: Paper of DL, RL, Graphs) which is our target variable. Each node is a representation of Bag-of-words for the words present in the individual paper. Bag-of-words or the node features are 1433-dimensional vector. Based on these features and edge connections related to citation, when a unknow type of paper comes into the network, we have to classify the type of paper. Below shown image can describe the problem in our hand where we have to predict the category of the new paper which probably should be Graph Neural Network as it cited the Deep Learning and Graph Mining papers.
First, we will explore the dataset then train a GCN network for node classification and finally we will also train a multilayer perceptron to compare the performance on the model in the test set. There are smaller number of datapoints to train, that’s why we are not batching the dataset instead directly running the epochs.
Do like, share and comment if you have any questions.